langchain
LangChain은 2022년 10월, 하버드 대학의 Harrison Chase가 주도한 LLM을 활용한 애플리케이션을 구축하기 위한 프레임워크입니다. LangChain핵심목표는 AI어플리케이션을 쉽고 빠르게 구현하는것입니다.예를 들면 Agent, QA시스템, 대햐형 로봇등등입니다. LangChain은 다양한 언어 모델과 도구들을 통합하여 복잡한 작업을 수행할 수 있도록 지원합니다.
왜서 langchain을 사용할까?
LangChain은 다음과 같은 이유로 사용됩니다:
- 모듈화: LangChain은 다양한 구성 요소(예: LLM, 프롬프트 템플릿, 메모리 등)를 모듈화하여 개발자가 쉽게 조합하고 확장할 수 있도록 합니다.
- 도구 통합: LangChain은 외부 도구(예: 검색 엔진, 데이터베이스 등)와의 통합을 지원하여 LLM의 기능을 확장합니다.
- 체인 구성: LangChain은 여러 단계를 거쳐 작업을 수행하는 체인을 쉽게 구성할 수 있도록 도와줍니다.
- 커뮤니티 및 생태계: LangChain은 활발한 커뮤니티와 다양한 플러그인 및 확장 기능을 제공하여 개발자가 최신 기술을 활용할 수 있도록 지원합니다.
langchain과 LLM직접 구현의 차이점
| 비교 항목 | 직접 대모델 API 호출 | LangChain 사용 개발 |
|---|---|---|
| 개발 방식 | 단순 작업에는 직관적이지만, 복잡한 기능은 많은 커스텀 코드 필요 | 모듈을 조합하는 방식으로 복잡한 기능도 쉽게 구현 가능 |
| 여러 모델 지원 | 모델 제공업체마다 다른 API를 직접 구현해야 함 | 통합 인터페이스 제공 → OpenAI, Anthropic, Hugging Face 등 쉽게 전환/조합 가능 |
| 외부 데이터 연동 | 데이터 로딩, 전처리, 벡터화, 검색 기능까지 모두 직접 구현해야 함 | PDF, DB, API 등과 쉽게 연결할 수 있는 RAG 기능과 다양한 도구 기본 제공 |
| 문맥(컨텍스트) 관리 | 대화 히스토리를 직접 관리해야 하며 Token 초과 위험 있음 | Memory 컴포넌트 제공 → 단기·장기 기억을 자동 관리 |
| 복잡한 작업 자동화 | 다단계 추론, 도구 호출 등을 구현하려면 논리 구조 설계가 어려움 | Agent 기능 제공 → 모델이 스스로 도구를 선택·호출해 작업 수행 |
| 운영(배포·모니터링) 지원 | 표준화된 디버깅/모니터링 도구 부족 | LangSmith로 추적, 디버깅, 평가, 모니터링 지원 |
langchain 아키텍처
- LangChain
- langchain
- Chains
- Agents
- Retrieval strategies
- langchain-community
- Model I/O
- Retrival
- Tool
- langchain-core
- LCEL(LangChain Expression Language)
- langchain
- LangGraph
- Directed Graph와 Conditional Edge를 기반으로 멀티에이전트 애플리케이션을 구축할수 있으려 조건 분기, 반복, 병렬 등 복잡한 제어 흐름을 지원한다, 또한 상태 지속성, 중단후 재실행, 시간여행, 인간-에이전트 협업과 같은 고급기능을 구현 할수 있다.
- LangSmith
- Debugging
- Playground
- Prompt Management
- Annotation
- Testing
- Monitoring
- LangServe LangChain개발한 chain, agent등을 쉽게 배포하고 운영할수 있도록 지원하는 서비스
LangChain 주요 컴포넌트
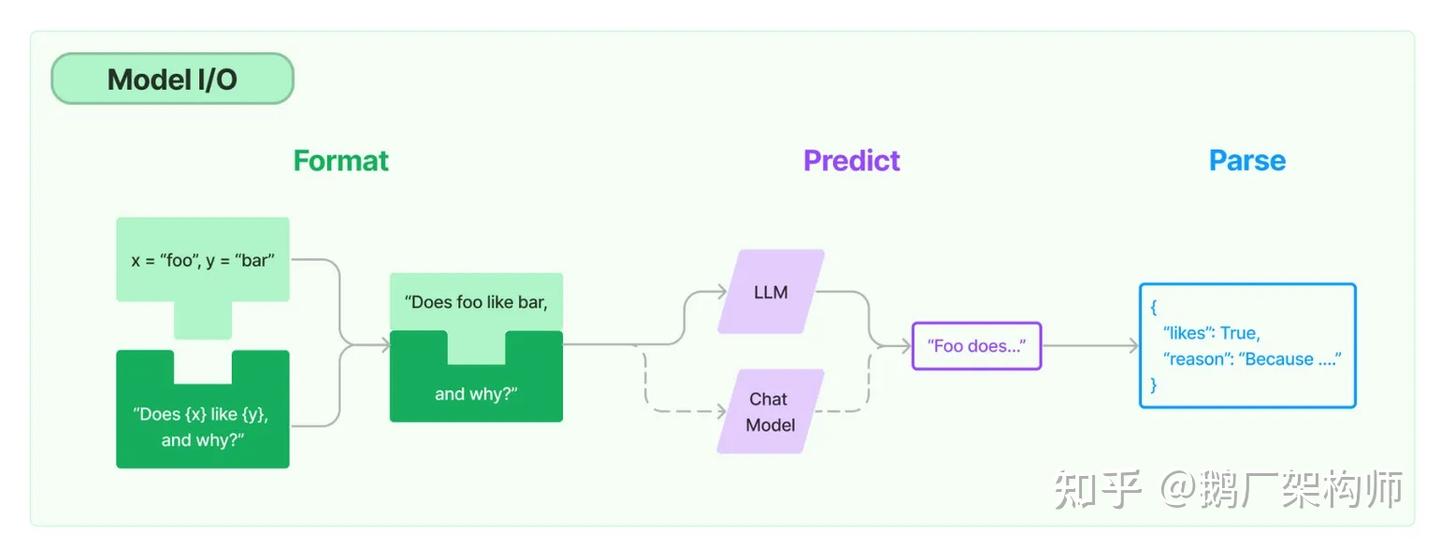
Model I/O
LLM모델과 상호작용 하는 컴포넌트로서 Format, Predict, Parse 단계가 있다. 대응하는 컴포넌트는 PromptTemplate, Model(LLM), OutputParser가 있다.
LLM 분류
- LLMs: 단순히 텍스트 생성
- Chat Models: 대화형 모델
- Embedding Models: 텍스트를 벡터로 변환
Message
- System Message: 모델의 동작방식을 정의
- Human Message: 사용자 입력
- AI Message: 모델의 응답
PromptTemplate
- Prompt: 모델에 전달되는 전체 텍스트
- PromptTemplate: 변수화된 프롬프트
- ChatPromptTemplate: 대화형 프롬프트 템플릿
- XxxMessagePromptTemplate: 특정 유형의 메시지에 대한 프롬프트 템플릿
- FewShotPromptTemplate: 몇 가지 예시를 포함하는 프롬프트 템플릿
OutputParser
- StrOutputParser: 단순 문자열 출력 파서
- JsonOutputParser: JSON 형식의 출력 파서
- CommaSeparatedListOutputParser: 쉼표로 구분된 리스트 출력 파서
- DatetimeOutputParser: 날짜 및 시간 출력 파서
- XmlOutputParser: XML 형식의 출력 파서
사용방식
- invoke: 단일 입력에 대한 예측 수행(ainvoke : 비동기 버전)
- stream: 스트리밍 출력을 지원하는 예측 수행(astream : 비동기 버전)
- batch: 배치 입력에 대한 예측 수행(abatch : 비동기 버전)
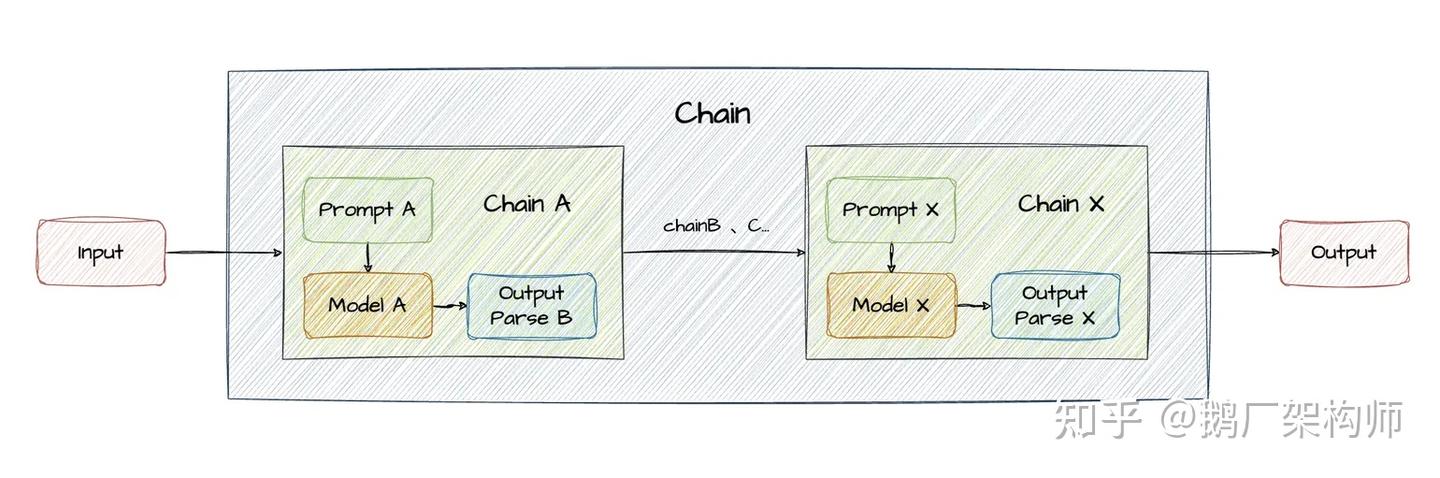
Chains
chain은 여러개 컴포넌트(prompt template, llm, memory, tool등)를 연결하여 특정 작업을 수행하는 단위입니다. chain에서 실행한 결과를 다음 체인에 전달하여 복잡한 작업을 수행할수 있습니다.
종류
- LLMChain: prompt템플릿과 LLM을 package화한 가장 기본적인 체인
- MultiPromptChain: 여러 개의 프롬프트 템플릿을 준비해두고, 입력을 **가장 적합한 프롬프트(템플릿)**로 LLM이 자동 선택하도록 하는 라우터.
- LLMRouterChain: LLM이 입력을 읽고, **어떤 체인(또는 프롬프트)**으로 보낼지 결정하는 Router Chain.
- EmbeddingRouterChain: 입력을 **임베딩(Embedding)**하여 미리 정의된 “주제 벡터들”과의 유사도 계산을 통해 어떤 체인으로 보낼지 결정하는 Router Chain.
- MultiRetrievalQaRouter: 여러 개의 Retriever(벡터DB or 검색 소스)를 준비해두고, 입력을 보고 어떤 Retriever에서 자료를 가져올지 라우팅하는 체인.
- SimpleSequentialChain: 여러개의 체인을 순차적으로 연결하여 실행, 앞 체인의 출력이 다음 체인의 입력.
- SequentialChain: 여러개의 체인을 순차적으로 연결하여 실행, 여러 입력·출력을 각각 지정
- RetrievalQA: Retriever로 문서를 검색한 뒤 LLM에 넣어 답변 생성.
- ConversationalRetrievalQAChain: 대화형 문맥을 유지하면서 Retriever로 문서를 검색한 뒤 LLM에 넣어 답변 생성.
- LCELChain: LangChain Expression Language(LCEL)을 사용하여 체인을 정의하는 방식
- StuffDocumentsChain: 여러 문서를 하나로 합쳐서 LLM에 전달하는 체인
- MapReduceDocumentsChain: 여러 문서를 각각 LLM에 전달하여 요약한 뒤, 그 요약들을 다시 LLM에 전달하여 최종 요약 생성
- MapReRankDocumentsChain: 여러 문서를 각각 LLM에 전달하여 점수를 매긴 뒤, 상위 문서들을 다시 LLM에 전달하여 답변 생성
- RefineChain: 초기 요약을 생성한 뒤, 추가 문서들을 순차적으로 반영하여 요약을 점진적으로 개선
- LLMMathChain: 수학 문제 해결을 위해 LLM과 계산기를 결합한 체인
- APIChain: API 호출을 위해 프롬프트 템플릿과 LLM을 결합한 체인
- SQLDatabaseChain: 데이터베이스 질의를 위해 프롬프트 템플릿, LLM, 데이터베이스 커넥터를 결합한 체인
- Hypothetical Document Embeddings: 문서의 가상 임베딩을 생성하여 검색 효율성을 높이는 체인
- VectorDBQAChain: 벡터 데이터베이스에서 문서를 검색한 뒤 LLM에 넣어 답변 생성
- ConversationalQAChain: 대화형 문맥을 유지하면서 LLM에 답변 생성
- TransformChain: 입력 데이터를 변환하는 함수를 체인에 통합
- LLMCheckerChain: LLM의 출력을 검증하는 체인
- AnalyzeDocumentChain: 문서를 분석하는 체인
- ConstitutionalChain: LLM의 출력을 헌법적 원칙에 따라 수정하는 체인
- ExtractionChain: 구조화된 데이터를 추출하는 체인
- LLMRequestChain: LLM에 대한 요청을 관리하는 체인 .....
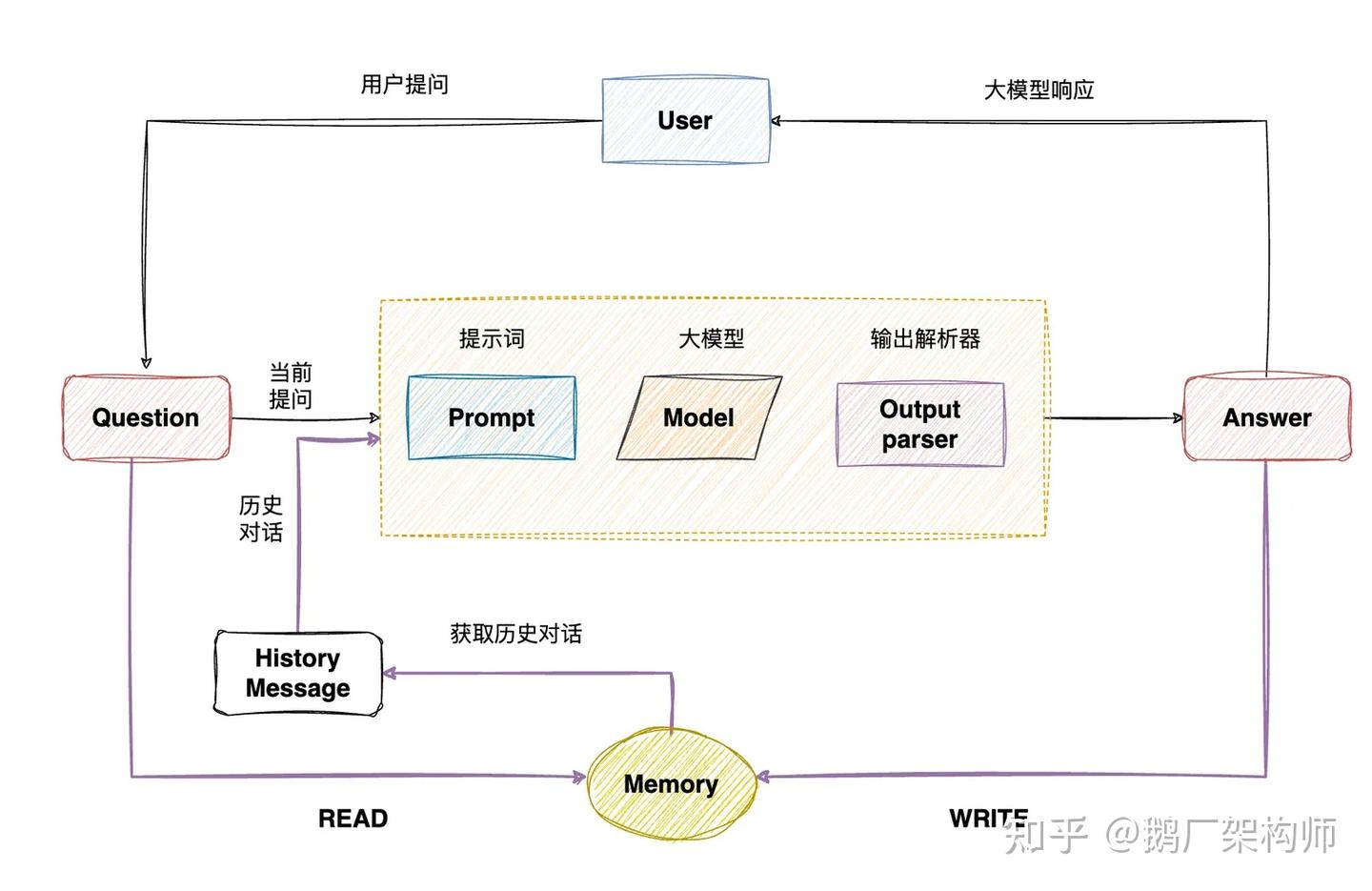
Memory
종류
| Memory 종류 | 설명 | 특징 | 장점 |
|---|---|---|---|
| ConversationBufferMemory | 전체 대화를 원문 그대로 저장하여 LLM에 전달하는 기본 메모리 | 단순 버퍼 방식, 시간순 메시지 저장 | 구현이 쉽고 맥락 전달이 가장 자연스러움 |
| ConversationBufferWindowMemory | 전체 이력을 보관하되 LLM에는 최근 N개 메시지만 전달 | 최근 맥락 중심, 비용 절감형 방식 | 최신 대화 맥락을 유지하면서 토큰 비용을 크게 줄일 수 있음 |
| ConversationSummaryMemory | 오래된 대화를 LLM이 *요약(summary)*하여 축약 저장 | 장기 대화에 최적화, 핵심 정보 중심 | 매우 긴 대화도 효율적으로 유지 가능하며 토큰 사용량 최소화 |
| ConversationSummaryBufferMemory | 오래된 대화는 요약, 최신 대화는 원문 유지하는 혼합형 메모리 | 요약 + 최근 메시지 버퍼 결합 | 자연스러운 대화 흐름 유지와 비용 절감을 동시에 실현 |
| ConversationKGMemory | 대화에서 엔티티·관계·사실을 추출해 지식 그래프(KG) 형태로 저장 | 구조적 지식 표현, 관계 기반 메모리 | 장기적 사실·관계를 명확하고 체계적으로 저장 가능 |
| VectorStoreRetrieverMemory | 대화를 임베딩하여 VectorStore에 저장 후 유사도 검색으로 관련 내용만 로드 | 벡터 기반 검색, 확장성 높음 | 매우 큰 대화 기록도 효율적으로 검색 가능하여 장기 기억에 강함 |
| EntityMemory | 대화에서 사람·사물·장소 등 엔티티 기반 정보를 추출해 저장 | 엔티티 중심 구조화 메모리 | 사용자 정보·속성·선호 등을 장기적으로 안정적으로 기억 |
| ChatMessageHistory | 메모리 구성에 사용되는 기본 메시지 히스토리 객체 | 단순 메시지 저장 구조 | 커스텀 메모리 개발 시 가장 유연하고 확장성이 좋음 |
| Custom Memory | BaseMemory를 상속해 직접 구현하는 맞춤형 메모리 | 완전 사용자 정의 가능 | 서비스 요구에 맞춘 고급 메모리 구조를 구축할 수 있음 |
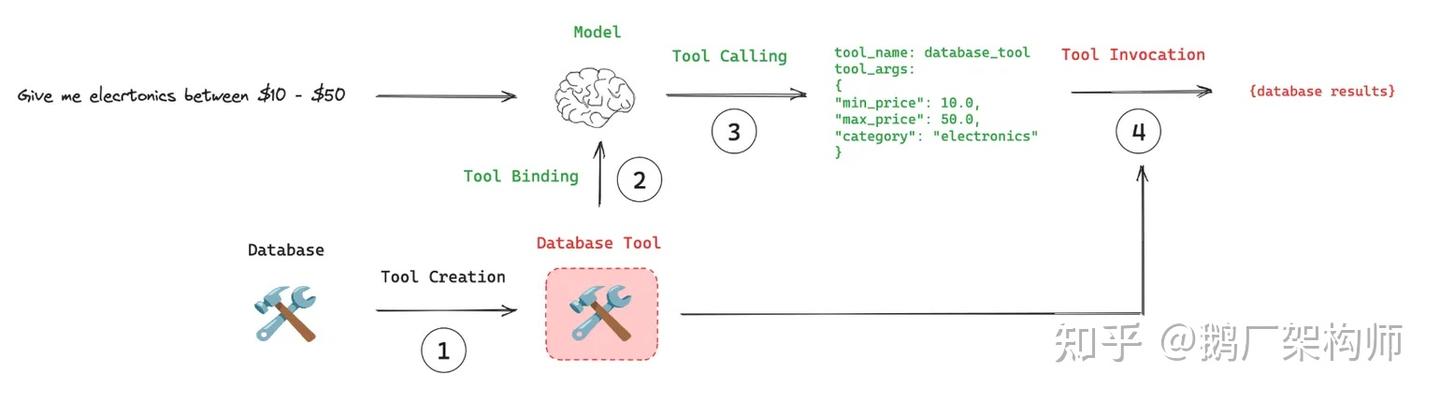
Tools
Tools는 LLM, Agent가 외부 시스템과 상호작용할수 있도록 도와주는 컴포넌트입니다. 본질은 함수(function)이며, 입력을 받아 특정 작업을 수행한후 출력을 반환합니다. 예를들어 검색도구, 계산기, 데이터베이스, API통신 등이 있습니다.
구성
- name: 도구 이름
- description: 도구에 대한 설명으로 프롬프트에 포함되어 LLM이 도구를 선택하는데 도움을 줌
- parameters: 도구에 전달되는 매개변수 정의
- return type: 도구가 반환하는 출력 형식
도구 호출 안되는 이슈
- LLM이 판단하기에 도구 호출이 필요하지 않다고 판단하는 경우
- 도구 설명이 모호하여 LLM이 적절한 도구를 선택하지 못하는 경우
- 일부 LLM 자체가 도구 호출을 선호하지 않는 경우(예: DeepSeek-R1)
해결: 도구에 대한 description이나 제시어를 바꿔 보거나 다른 LLM을 사용
langchain tool과 MCP Server차이점
| 비교 항목 | 내장 Tools | MCP Server |
|---|---|---|
| 배포 위치 | 에이전트 내부(동일 프로세스) | 독립 서비스(별도 프로세스/네트워크) |
| 코드 결합도 | 강한 결합(직접 코드 참조) | 느슨한 결합(프로토콜 기반 통신) |
| 재사용성 | 해당 에이전트에서만 사용 가능 | 여러 에이전트 간 공유 가능 |
| 업데이트 및 유지보수 | 수정 시 에이전트 재빌드 필요 | 독립적으로 업데이트 가능, 에이전트 재빌드 불필요 |
| 성능 | 로컬 직접 호출로 매우 빠름 | 네트워크/IPC 통신 필요로 상대적으로 느림 |
| 적합한 사용 시나리오 | 단순·특화 기능 도구 | 범용·복잡·확장 가능한 도구 |
Agents
에이전트는 LLM과 도구를 결합하여 복잡한 작업을 수행하는 컴포넌트입니다. 에이전트는 사용자의 입력을 받아 적절한 도구를 선택하고 호출하여 작업을 수행한 후 결과를 반환합니다.
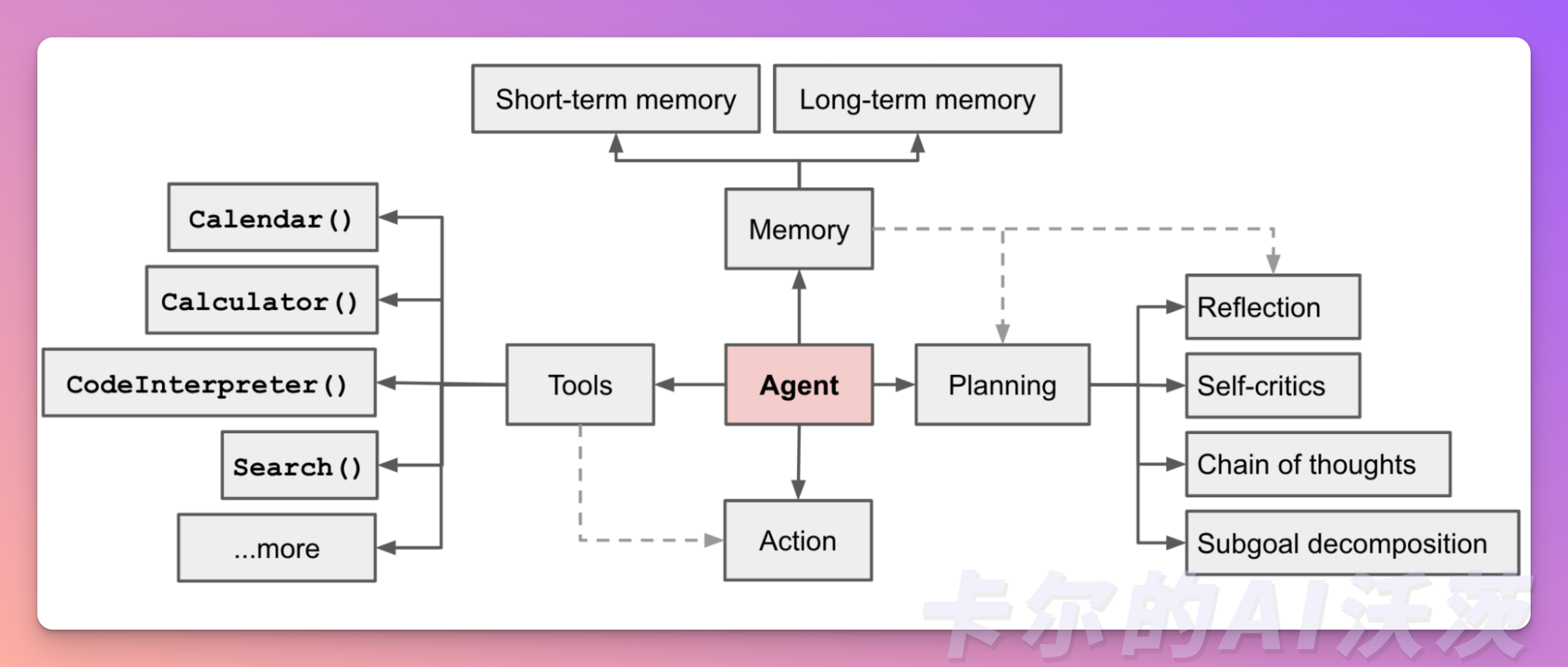
구성요소
- Memory 관리: 대화형 에이전트는 Memory컴포넌트를 사용하여 대화 히스토리를 관리하고 문맥을 유지합니다.
- short-term memory: 최근 대화 내용을 기억
- long-term memory: 장기적인 정보나 사실을 기억
- Tools 활용: 에이전트는 다양한 도구를 활용하여 외부 시스템과 상호작용하고 복잡한 작업을 수행합니다.
- Planning: 에이전트는 작업을 여러 단계로 나누어 계획을 세우고 실행할 수 있습니다.
- Reflection
- Self-critics
- Chain of Thoughts
- Subgoal decomposition
- Action and Observation: 에이전트는 도구를 호출하고 그 결과를 관찰하여 다음 행동을 결정합니다.
Deepagents
deepagents는 복잡하고 다단계 작업을 처리할 수 있는 에이전트를 구축하기 위한 독립형 라이브러리입니다.
사용해야 하는 경우
- 계획 및 분해가 필요한 복잡하고 다단계 작업을 처리할 때
- 파일 시스템 도구를 통해 대량의 컨텍스트를 관리할 때
- 컨텍스트 격리를 위해 특수 하위 에이전트에 작업을 위임할 때
- 대화 및 스레드 간에 메모리를 유지할 때
핵심 역량
- 계획 및 분해: 작업을 여러 단계로 나누어 계획을 세우고 실행
- Context관리: 파일 시스템 도구를 통해 대량의 컨텍스트 관리
- 하위 에이전트: 특수 하위 에이전트를 통해 작업 위임 및 컨텍스트 관리
- Long-term memory: LangGraph의 Store를 사용하여 스레드 간에 영구 메모리를 확장
예제
참고
Retrieval Augmented Generation
Retrieval은 외부 지식 소스에서 관련 정보를 검색하여 LLM에 제공하는 컴포넌트입니다. 이를 통해 모델이 최신 정보에 접근하거나 도메인 특화 지식을 활용할 수 있습니다. LLM은 학습동결 모델이기 때문에 사전학습된 지식 외의 정보를 제공하려면 Retrieval기능이 필수적입니다. 또한 환각 문제를 완화하는데도 도움이 됩니다. RAG(Retrieval Augmented Generation)시스템의 핵심 구성 요소입니다.
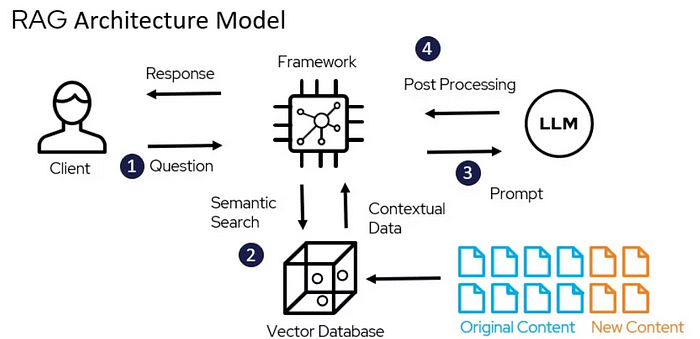
Retrieval Augmented Generation 흐름1
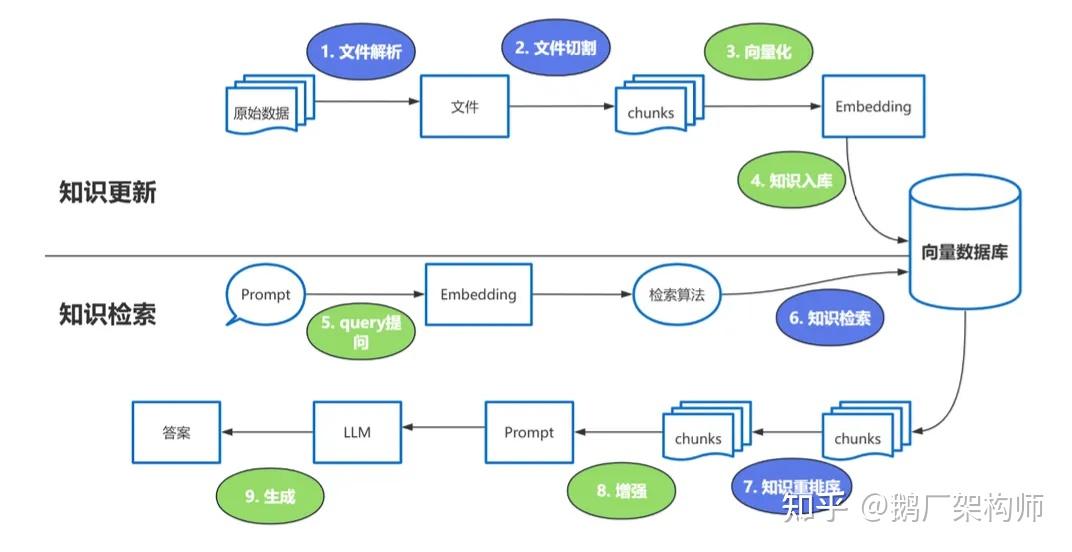
-
문서 파싱
-
텍스트 분할
-
백터화(EmbeddingModel사용)
- nomic-embed-text
- mxbai-embed-large
- embedding-gemma
-
벡터 DB 저장
-
질문
-
검색알고리즘(Cosine Similarity, Dot Product, Euclidean Distance 등)
-
지식 재배치(RerankModels): 유사한 값이 높은 순으로 정렬
-
증강: 사용자 질문과 함께 검색된 내용을 LLM에 전달
-
응답 생성
Retrieval Augmented Generation 장점
- 실시간 업데이트
- 비용 대비 효율성
- 출처를 제공하는 응답이여서 믿음직함
- 안전하고 제어 가능: 제공한 문서에 기반한 응답만 생성 가능하게 제어 가능
Retrieval Augmented Generation 단점
- 검색품질의 한계
- 시스템 복잡도 증가
- context가 영향을 받음
- 제공한 문서의 영향도가 큼
langchain에서 구현
- Document Loaders
- page_content: 문서의 실제 텍스트 내용
- metadata: 문서에 대한 추가 정보
-
Text Splitters
작동 원리
우선 세분화한 후 병합하는 전략을 따릅니다. 먼저 텍스트를 작은 문장 단위로 분할한 다음, 이러한 문장들을 순서대로 결합하여 설정된 블록 크기 제한에 도달할 때까지 더 큰 블록으로 만듭니다. 새 블록을 생성할 때는 이전 블록과 일부 중복되는 부분을 유지하여 문맥의 연속성을 보장합니다.
왜 구분이 필요한가
- 생성된 답변의 품질 보장: 검색된 텍스트 블록이 너무 크고 관련 없는 정보가 많으면 LLM이 관련 없는 내용에 방해를 받아 핵심 문제에 집중하지 못할 수 있습니다. 심지어 관련 없는 정보를 잘못 통합하여 부정확하거나 장황한 답변을 생성할 수도 있습니다.
- 모델의 컨텍스트 창 제한 극복: 모든 대형 모델에는 고정된 컨텍스트 창이 있으며, 이는 모델이 한 번에 "보고" 처리할 수 있는 텍스트의 총량이 제한되어 있음을 의미합니다.
- 검색 정확도 향상: 검색 시스템은 특정 질문에 답할 수 있는 단락을 직접 찾을 수 있어 검색 결과의 관련성과 정확성을 크게 향상시킵니다.
langchain의 Text Splitters
- TextSplitter: LangChain에서 모든 텍스트 분할기의 기반이 되는 추상(Base) 클래스입니다.
- CharacterTextSplitter: 문자/문단 단위로 단순하게 분할하는 기본 방식.
- RecursiveCharacterTextSplitter: 여러 분리자를 계층적으로 적용하여 자연스럽게 텍스트를 분할하는 권장 방식.
- TokenTextSplitter: 토큰 개수 기준으로 텍스트를 분할하는 방식(OpenAI 등 토큰 제한 대응).
- LatexTextSplitter: LaTeX 문서 프로그래밍 언어를 이해
- MarkdownTextSplitter: Markdown 구조를 이해
-
Text Embedding Models(모델: nomic-embed-text등등.)
-
Vector Stores
- 저장
- 검색
- Retrievers Vector Stores가 함수 제공(알고리즘포함)
Callbacks
기타 미정리
chunk
- chunkSize
- chunkOverlap

MMR
LangChain 支持对检索结果进行基于 maximum marginal relevance(MMR,最大边界相关法)的重新排序
多查询检索
以距离为度量的向量数据库检索,是通过将 query 进行 embedding(表征)到高维的向量空间,然后基于距离检索相似文档(embedding 到相同向量空间)。
但有时 query 中词语的轻微改变,或者 embedding 无法很好地捕获 query 的语义信息,那么将导致无法有效检索到相似文档。 而多 query 检索便是应对这个问题,会通过提示词工程,将 query 输入到 LLM 从不同角度生成多个类似的查询,再分别用多个 query 去进行检索,然后汇聚这些检索结果,并进行去重,这样能够获取更多潜在的相似文档。