Retrieval Augmented Generation
Retrieval Augmented Generation
Retrieval은 외부 지식 소스에서 관련 정보를 검색하여 LLM에 제공하는 컴포넌트입니다. 이를 통해 모델이 최신 정보에 접근하거나 도메인 특화 지식을 활용할 수 있습니다. LLM은 학습동결 모델이기 때문에 사전학습된 지식 외의 정보를 제공하려면 Retrieval기능이 필수적입니다. 또한 환각 문제를 완화하는데도 도움이 됩니다. RAG(Retrieval Augmented Generation)시스템의 핵심 구성 요소입니다.
- 줄여서 얘기하면 검색기술 + LLM 제시어
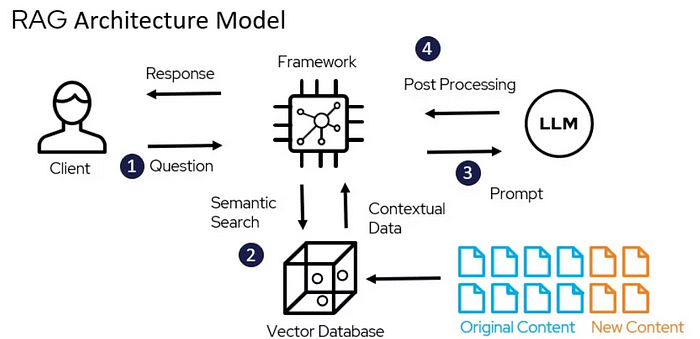
Retrieval Augmented Generation 흐름
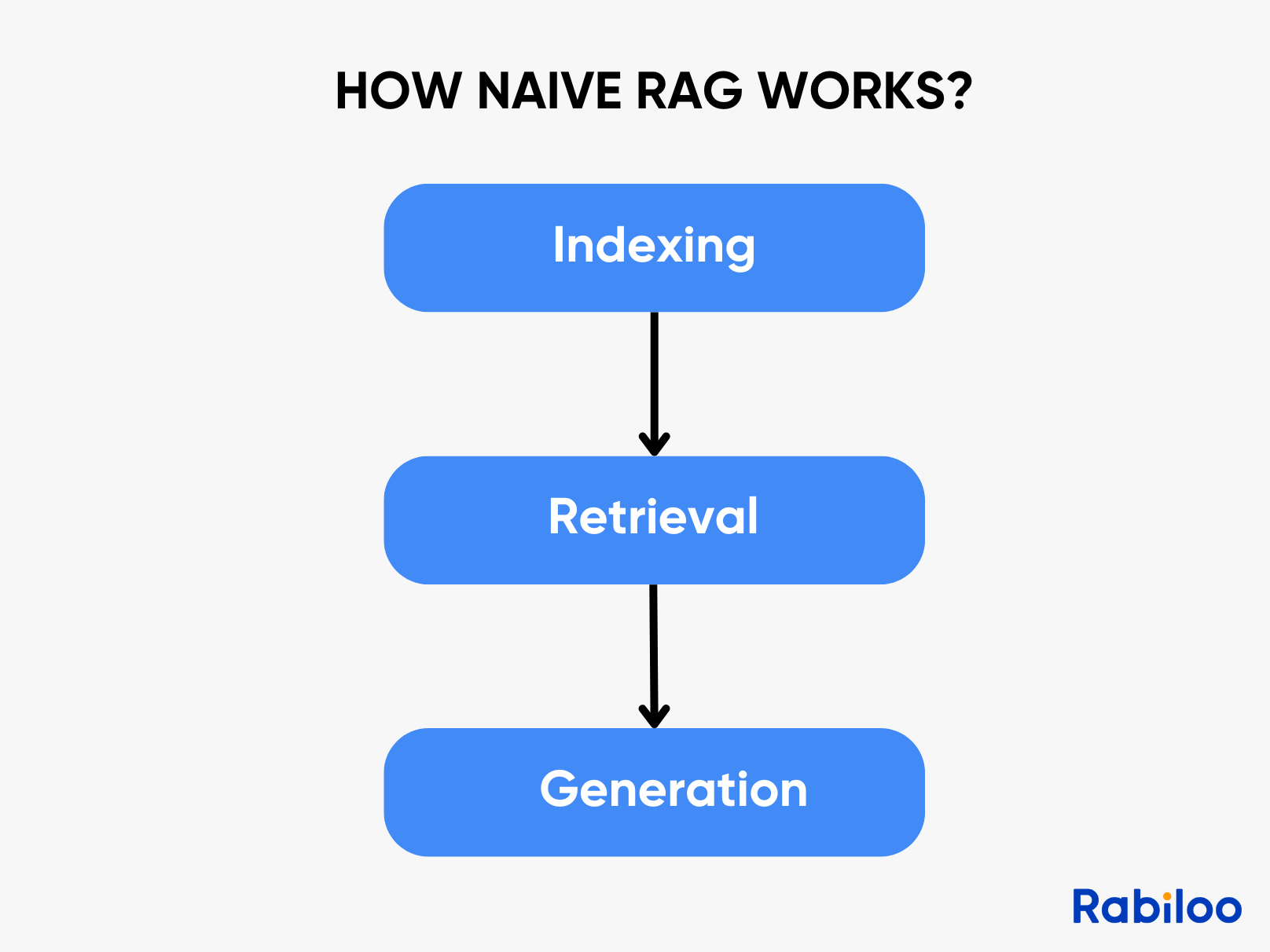
- 문서 파싱
- 텍스트 분할
- 백터화(EmbeddingModel사용)
- 벡터 DB 저장
- 질문
- Retrieval
- 검색알고리즘 사용(Cosine Similarity, Dot Product, Euclidean Distance 등)
- 증강: 사용자 질문과 함께 검색된 내용을 LLM에 전달
- 응답 생성
Retrieval Augmented Generation 장점
- 실시간 업데이트
- 비용 대비 효율성
- 출처를 제공하는 응답이여서 믿음직함
- 안전하고 제어 가능: 제공한 문서에 기반한 응답만 생성 가능하게 제어 가능
Retrieval Augmented Generation 단점
- 검색품질의 한계
- 시스템 복잡도 증가
- context가 영향을 받음
- 제공한 문서의 영향도가 큼
Advanced RAG
기본 RAG 방식에서 검색전, 검색중, 검색후 과정이 추가됨
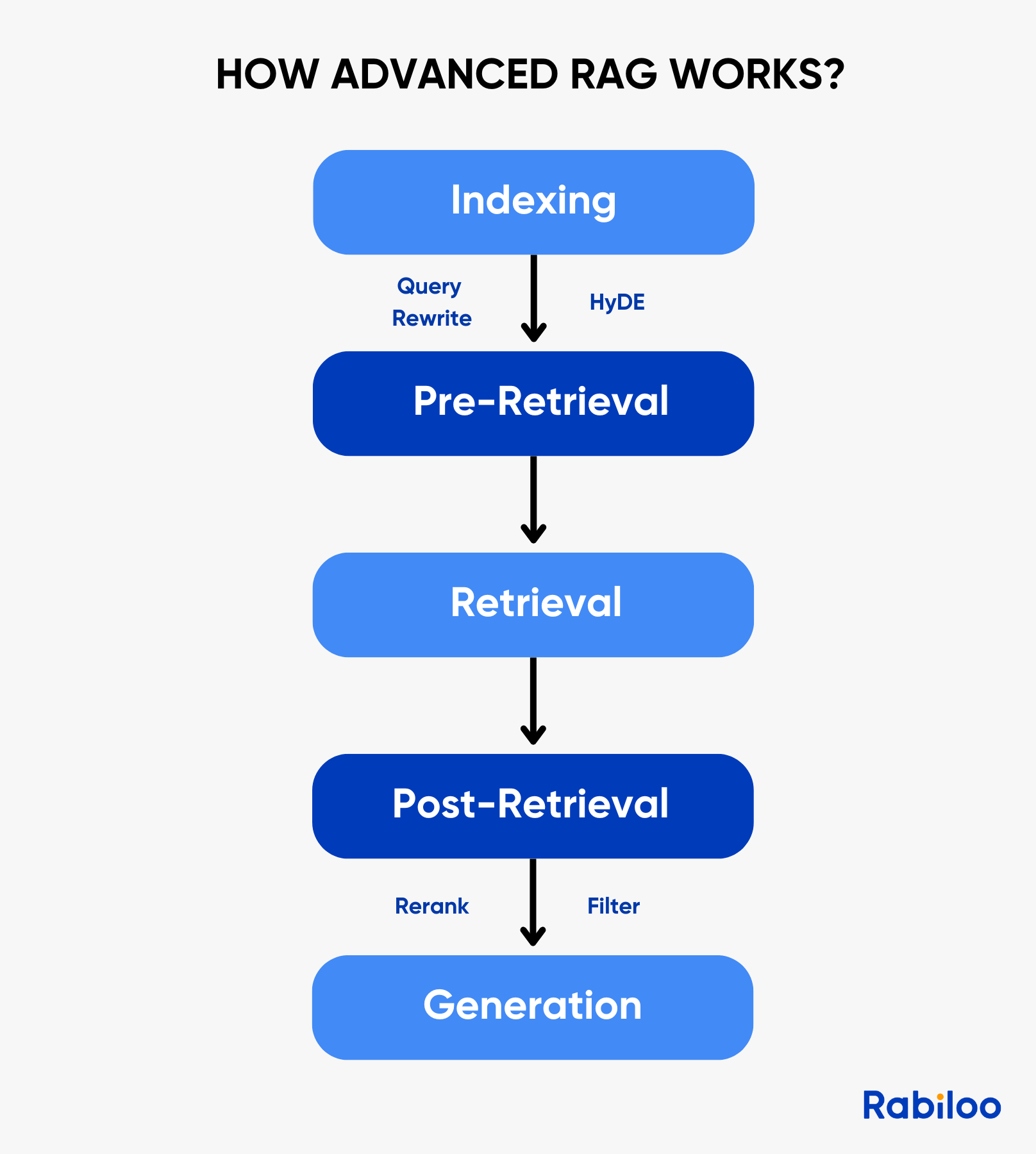
-
Pre-Retrieval
- Query Rewriting
- HyDE
-
Retrieval
- 검색알고리즘 혼합사용(Cosine Similarity, Dot Product, Euclidean Distance 등)
-
Post-Retrieval
- Rerank(RAG-Fusion, Cohere)
- Filter
- Context 최적화
RAG-Fusion
- 여러 쿼리 생성: 사용자의 원래 질문을 대규모 언어 모델(LLM)이 여러 가지 다른 관점이나 표현을 가진 하위 질문들로 다시 작성합니다. 예를 들어, "MEMS 마이크로폰"에 대해 물으면 "MEMS 마이크로폰이란 무엇인가요?", "MEMS 마이크로폰의 장점은 무엇인가요?"와 같은 질문을 생성할 수 있습니다.
- 독립적인 검색: 생성된 각각의 하위 질문을 사용하여 문서 데이터베이스에서 관련 문서를 독립적으로 검색합니다. 이 과정에서 벡터 검색, 키워드 검색 등 다양한 검색 전략이 활용될 수 있습니다.
- 결과 융합 및 재순위(Reranking): 각 검색 결과 목록을 RRF(Reciprocal Rank Fusion)라는 알고리즘을 사용하여 단일의 통합된 순위 목록으로 병합하고 재정렬합니다. RRF는 순위가 높은 문서에 더 높은 점수를 부여하여 가장 관련성이 높은 문서가 상단에 오도록 보장합니다.
- 최종 답변 생성: 이렇게 융합 및 재순위된 문서를 원래 질문과 함께 LLM에 입력하여 최종적이고 일관성 있는 답변을 생성합니다.
HyDE - 가상 문서 임베딩(Hypothetical Document Embeddings)
- 장점
- 검색 품질 향상: 일반 RAG는 질문 그대로 벡터화해 검색하지만, 질문이 짧거나 모호한 경우 검색 품질이 떨어질 수 있습니다. HyDE는 LLM이 질문을 한 번 ‘확장’하여 더 풍부한 정보를 가진 문서를 만들어 주기 때문에 관련성이 높은 문서를 훨씬 잘 찾아냅니다.
- 희소하거나 구조화되지 않은 데이터에서 강함: 정확한 문장이 데이터베이스에 없어도 가상의 문서가 ‘중간 브리지(bridge)’ 역할을 하여 비슷한 주제의 문서를 더 잘 매칭할 수 있습니다.
- 쿼리 확장 효과(Query Expansion): 질문자가 떠올리지 못한 개념들을 LLM이 가상 문서에서 미리 언급해 줌으로써 검색 정보량과 정확도가 증가합니다.
- 도메인 지식이 부족한 사용자에게 유리: 사용자가 전문 용어나 정확한 키워드를 모르는 경우에도 HyDE가 질문을 보완해 주어 전문지식 기반 문서를 잘 검색할 수 있게 해줍니다.
Rerank(Model, library)
- Cohere Rerank v3.5
- bge-reranker-large / base
- Voyage rerank
- OpenAI의 Rerank 기능 (latest)
- https://ollama.com/search?q=rerank
Context Compression
- (기법) LLM Summarization: 문서 길이를 줄이면서 핵심만 유지
- (기법) Extractive Compression: 원문에서 쓸모없는 문장 제거
- (기법) Sentence-level similarity filtering (문장 단위 relevance scoring)
- (도구) LangChain의 Contextual Compression Retriever
- (도구) LlamaIndex의 SentenceWindowRetriever, ContextFilter
Context Filtering
- (기법) 질문과 관련성 낮은 문서 삭제
- (기법) 중복 문서 제거
- (기법) 동일 문장의 paraphrase 제거
- (기법) 너무 오래된 정보 제거
- (기법) metadata 기반 필터링 (날짜/카테고리)
Chunk Merging & Re-chunking
- (도구) LlamaIndex AutoMergingRetriever
- (도구) LangChain ParentDocumentRetriever
Context Ordering
- 가장 관련성 높은 순서
- 출처별 그룹화
- 최신 정보 먼저
- 짧고 강한 문헌 먼저
- 최신 → 근접 → 포괄 순
RAGAS - Retrieval-Augmented Generation Assessment
- 평가 지표
- ContextRelevance: context 관련성
- ContextEntityRecall: context 유실여부
- ContextPrecision: context 정확성
- Faithfulness: 답변정확도, context에 근거해서 답변을 하는지.
- ResponseRelevance: 결과 관련성
- AnswerCorrectness: 답변 정확성
- SemanticSimilarity: 생성된 정답과 실제 정답의 의미적 유사도를 평가
- 기타 등등...
Modular RAG
RAG의 모든 단계를 모듈화하여, 교체·조합·최적화가 가능한 구조적인 RAG 시스템
PageIndex
PageIndex는 인간 전문가가 복잡한 문서를 탐색하고 지식을 추출하는 방식을 시뮬레이션하는 추론 기반 검색 시스템입니다.
문서를 계층적 트리 구조 색인으로 변환하고 LLM이 해당 구조에 대한 추론을 통해 관련 정보를 검색할 수 있도록 합니다.
참고
- https://www.llamaindex.ai/llamaparse
- https://zhuanlan.zhihu.com/p/722159912
- https://rabiloo.com/blog/the-3-types-of-rag-models-naive-rag-modular-rag-and-advanced-rag --https://zhuanlan.zhihu.com/p/1924487055976670911
- https://www.zhihu.com/search?type=content&q=rag 如何评估
- https://zhuanlan.zhihu.com/p/1975321777342260763
- https://zhuanlan.zhihu.com/p/1956865613138986501
- https://zhuanlan.zhihu.com/p/1920459703399462751
- https://zhuanlan.zhihu.com/p/675509396
- https://zhuanlan.zhihu.com/p/27274703035